Jiancheng DongGreetings! I am currently a first-year Ph.D. student at the City University of Hong Kong, where I am fortunate to be advised by Prof. Xiangyu Zhao. Previously, I received my bachelor's degree from the School of Artificial Intelligence at Nanjing University. My research interests primarily lie in LLMs, with a specific focus on long sequence compression and packing. Currently, I am also a Scientist Intern at Baidu Inc., Search Science, working closely with Lixin Su, Shuaiqiang Wang, and Dawei Yin. |

|
Selected PublicationsFor the full publication list, please refer to my Google Scholar. |
|
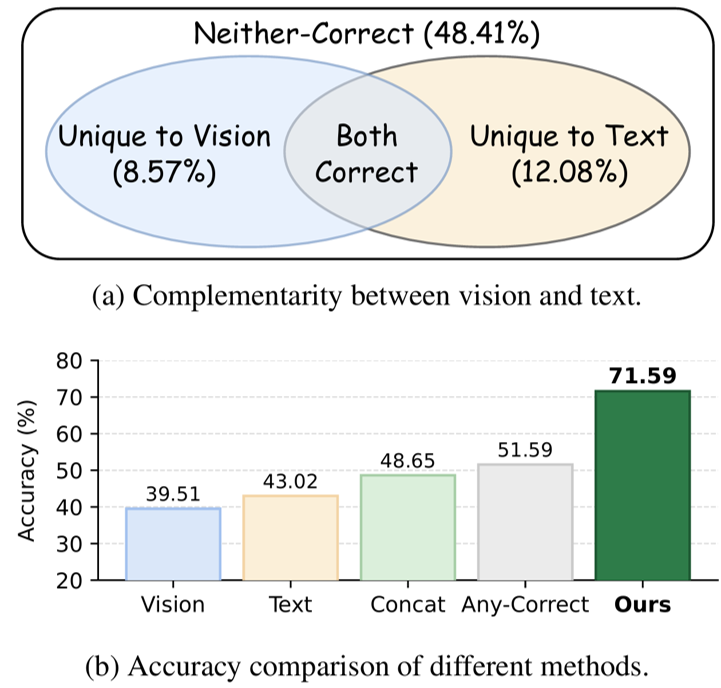
How to Utilize Complementary Vision-Text Information for 2D Structure UnderstandingJiancheng Dong, Pengyue Jia, Derong Xu, Jiawei Cheng, Jingyu Peng, Chao Zhang, Bowen Liu, Xin Sun, Lixin Su, Shuaiqiang Wang, Dawei Yin, Xiangyu Zhao In submission, 2026 I developed DiVA-Former , a lightweight framework for compressing long structured contexts in LLMs. It uses visual tokens as dynamic queries to distill lengthy serialized table text into compact digest vectors, reducing context length and computational burden while preserving both structural cues and fine-grained textual information. |
|
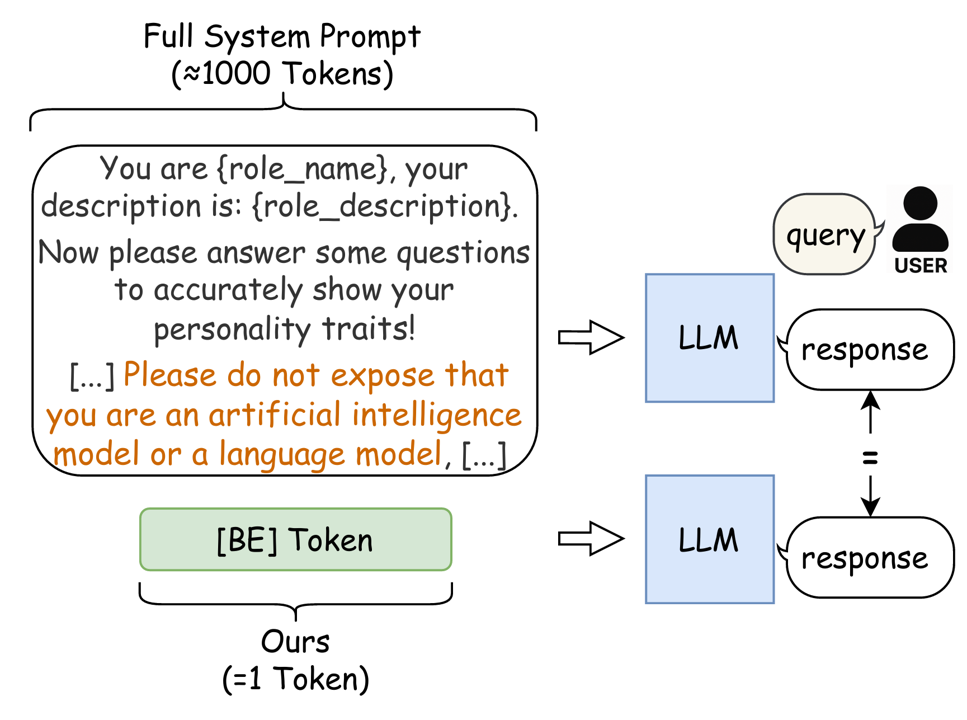
Behavior-Equivalent Token: Single-Token Replacement for Long Prompts in LLMsJiancheng Dong, Pengyue Jia, Jingyu Peng, Maolin Wang, Yuhao Wang, Lixin Su, Xin Sun, Shuaiqiang Wang, Dawei Yin, Xiangyu Zhao In submission, 2025 arxiv / I developed Behavior-Equivalent Token, a context-compression method that learns a single token to replace long system prompts while preserving their behavioral effect on downstream tasks. This significantly reduces prompt overhead , improves inference efficiency, and frees up more context budget for user inputs in LLM applications. |
|
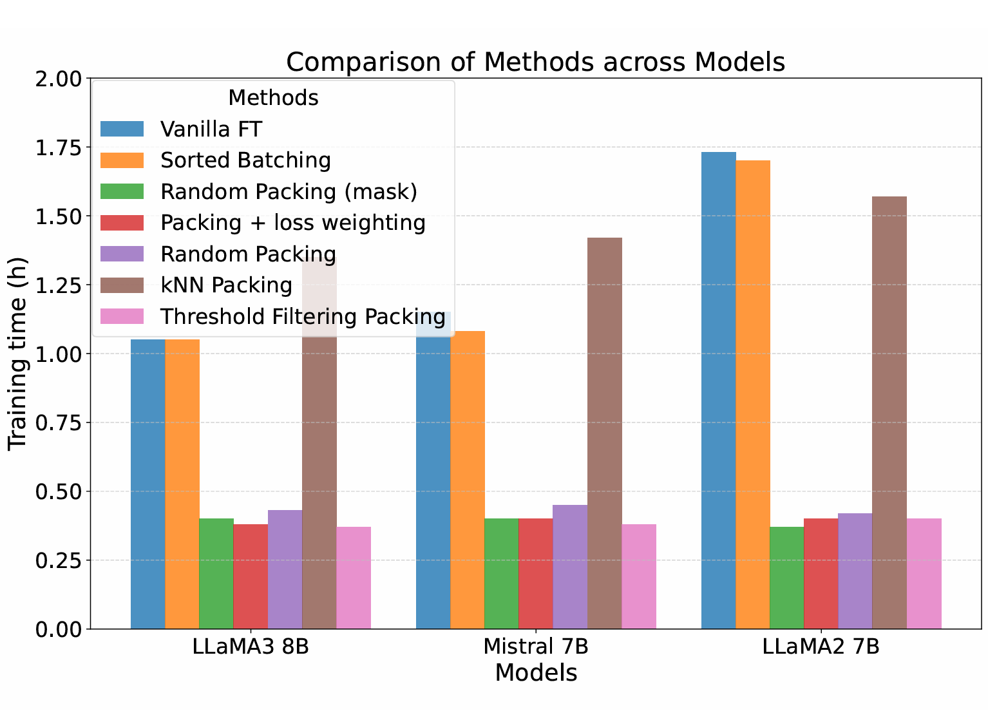
Threshold Filtering Packing for Supervised Fine-Tuning: Training Related Samples within PacksJiancheng Dong, Lei Jiang, Wei Jin, Lu Cheng NAACL main, 2025 arxiv / I developed Threshold Filtering Packing for supervised fine-tuning, a packing strategy that groups relevant but diverse samples within each training pack. The method is designed to reduce cross-sample interference during packed training and improve training efficiency and data organization, which is especially relevant to long-sequence, efficiency-sensitive large-model training. |
InternshipThese are my internship experiences. |
|
|
Baidu Inc., Search ScienceResearch Intern 5/2025 -- 2/2026 Advisors: Lixin Su, Shuaiqiang Wang, and Dawei Yin Focused on context compression; developed Behavior-Equivalent Token to equivalently replace complex long prompts, retaining 98% performance at compression ratios up to 3000×. Expanded research to visual-text compression; leveraged the complementarity between textual and visual modalities to develop DiVA-Former, which improves upon the pure-text baseline by 23.9%. |

|
University of Illinois Chicago, Responsible and Reliable AI LabResearch Assistant 3/2024 -- 9/2024 Advisors: Prof. Lu Cheng and Wei Jin Developed the Threshold Filtering Packing method to reduce sequence cross-contamination, enhancing contextual learning and improving the utilization of training data. Conducted research in Trustworthy AI and LLM Fairness, investigating data-centric optimization strategies to mitigate demographic bias amplification during LLM Alignment. |

|
Nanjing University, Natural Language Processing GroupResearch Intern 4/2023 -- 1/2024 Advisors: Prof. Xinyu Dai and Prof. Zhen Wu Explored data selection strategies for instruction tuning, aiming to optimize sample relevance and diversity while conducting preliminary experiments to identify methods for improving data efficiency. |
|
Design and source code from Jon Barron's website |